![]()
CRISP-ML(Q). The ML Lifecycle Process.
The machine learning community is still trying to establish a standard process model for machine learning development. As a result, many machine learning and data science projects are still not well organized. Results are not reproducible. In general, such projects are conducted in an ad-hoc manner. To guide ML practitioners through the development life cycle, the Cross-Industry Standard Process for the development of Machine Learning applications with Quality assurance methodology (CRISP-ML(Q)) was recently proposed. We review the core phases of the ML development process model (see Figure 1). There is a particular order of the individual stages. Still, machine learning workflows are fundamentally iterative and exploratory, so that depending on the results from the later phases, we might re-examine earlier steps.
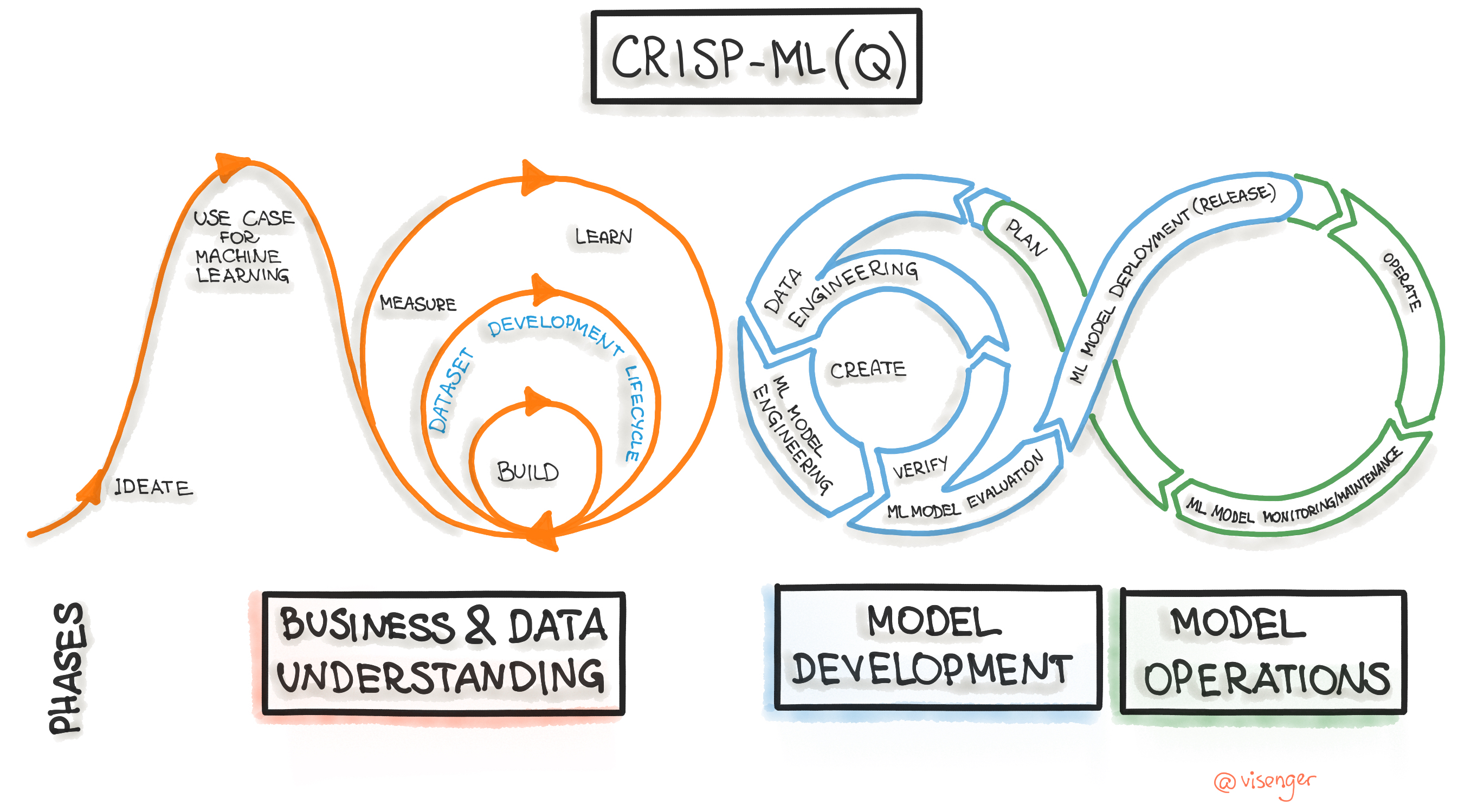 Figure 1: Machine Learning Development Life Cycle Process.
Figure 1: Machine Learning Development Life Cycle Process.
Overall, the CRISP-ML(Q) process model describes six phases:
- Business and Data Understanding
- Data Engineering (Data Preparation)
- Machine Learning Model Engineering
- Quality Assurance for Machine Learning Applications
- Deployment
- Monitoring and Maintenance.
For each phase of the process model (see Figure 2), the quality assurance approach in CRISP-ML(Q) requires the definition of requirements and constraints (e.g., performance, data quality requirements, model robustness, etc.), instantiation of the specific tasks (e.g., ML algorithm selection, model training, etc.), specification of risks that might negatively impact the efficiency and success of the ML application (e.g., bias, overfitting, lack of reproducibility, etc.), quality assurance methods to mitigate risks when these risks need to be diminished (e.g., cross-validation, documenting process and results, etc.).
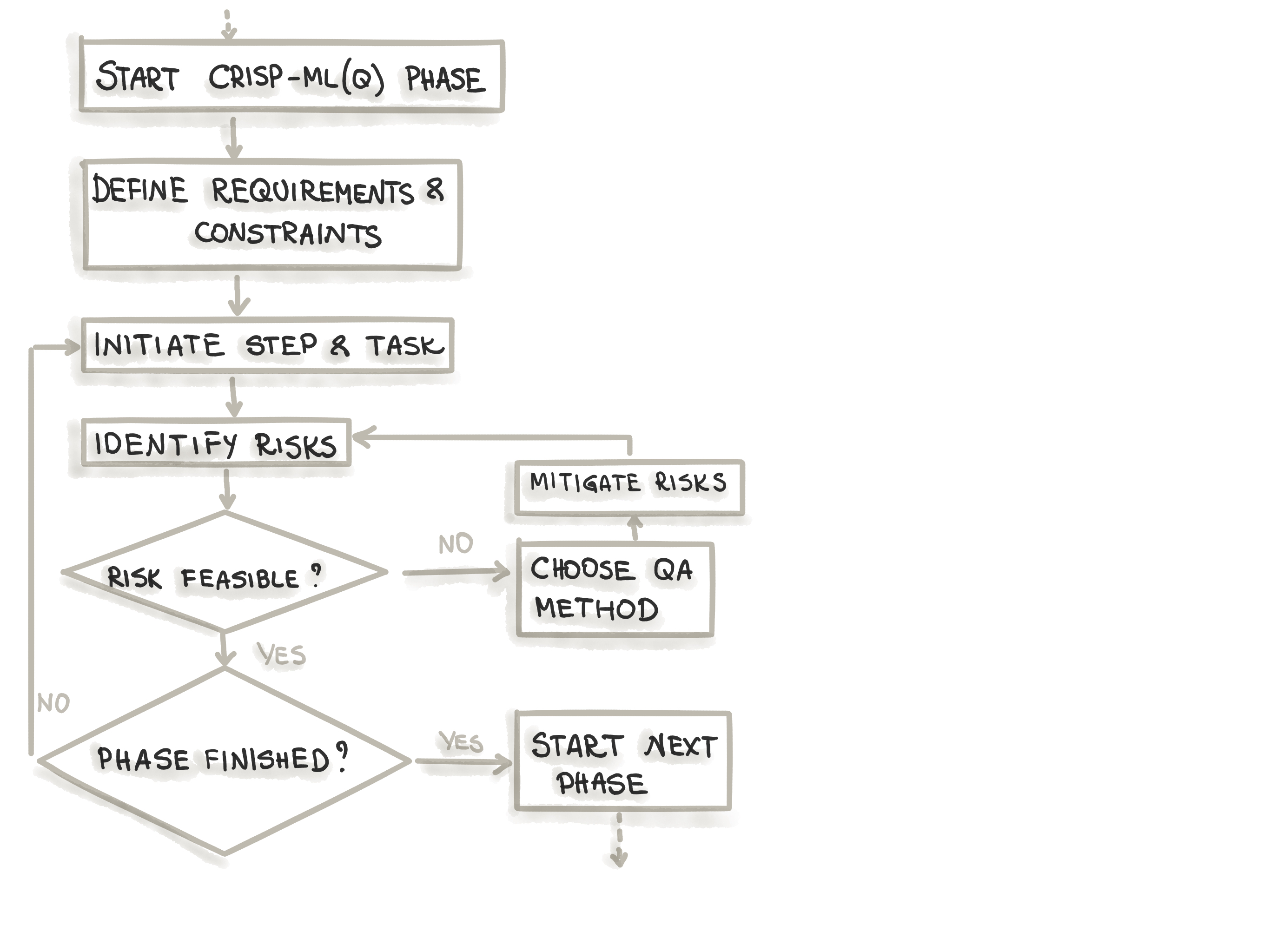 Figure 2: CRISP-ML(Q) approach for quality assurance for each of the six phases.
Figure 2: CRISP-ML(Q) approach for quality assurance for each of the six phases.
In the following, we describe each of the six CRISP-ML(Q) stages with respect to the quality assurance structure.
Business and Data Understanding
Developing machine learning applications starts with identifying the scope of the ML application, the success criteria, and a data quality verification. The goal of this first phase is to ensure the feasibility of the project.
We gather success criteria along with business, machine learning, and economic success criteria during this phase. These criteria are required to be measurable. Therefore, defining clear and measurable Key Performance Indicators (KPI) such as “time savings per user and session” is required. A helpful approach is to define a non-ML heuristic benchmark to communicate the impact of machine learning tasks with the business stakeholders.
Confirming the feasibility before setting up the ML project is a best practice in an industrial setting. Applying the Machine Learning Canvas framework would be a structured way to perform this task. The ML Canvas guides through the prediction and learning phases of the ML application. In addition, it enables all stakeholders to specify data availability, regulatory constraints, and application requirements such as robustness, scalability, explainability, and resource demand.
As data guides the process, data collection and data quality verification are essential to achieving business goals. Therefore, one crucial requirement is the documentation of the statistical properties of data and the data generating process. Similarly, data requirements should be stated and documented as well, as it becomes a foundation for data quality assurance during the operational phase of the ML project.
Data Engineering (Data Preparation)
The second phase of the CRISP-ML(Q) process model aims to prepare data for the following modeling phase. Data selection, data cleaning, feature engineering, and data standardization tasks are performed during this phase.
We identify valuable and necessary features for future model training by using either filter methods, wrapper methods, or embedded methods for data selection. Furthermore, we select data by discarding samples that do not satisfy data quality requirements. At this point, we also might tackle the problem of unbalanced classes by applying over-sampling or under-sampling strategies.
The data cleaning task implies that we perform error detection and error correction steps for the available data. Adding unit testing for data will mitigate the risk of error propagation to the next phase. Depending on the machine learning task, we might need to perform feature engineering and data augmentation activities. For example, such methods include one-hot encoding, clustering, or discretization of continuous attributes.
The data standardization task denotes the process of unifying the ML tools’ input data to avoid the risk of erroneous data. Finally, the normalization task will mitigate the risk of bias to features on larger scales. We build data and input data transformation pipelines for data pre-processing and feature creation to ensure the ML application’s reproducibility during this phase.
Machine Learning Model Engineering
The modeling phase is the ML-specific part of the process. This phase aims to specify one or several machine learning models to be deployed in the production. The translation to the ML task depends on the business problem that we are trying to solve. Constraints and requirements from the Business and Data Understanding phase will shape this phase. For example, the application domain’s model assessment metrics might include performance metrics, robustness, fairness, scalability, interpretability, model complexity degree, and model resource demand. We should adjust the importance of each of these metrics according to the use case.
Generally, the modeling phase includes model selection, model specialization, and model training tasks. Additionally, depending on the application, we might use a pre-trained model, compress the model, or apply ensemble learning methods to get the final ML model.
One main complaint about machine learning projects is the lack of reproducibility. Therefore we should ensure that the method and the results of the modeling phase are reproducible by collecting the model training method’s metadata. Typically we collect the following metadata: algorithm, training, validation and testing data set, hyper-parameters, and runtime environment description. The result reproducibility assumes the validation of the model’s mean performance on different random seeds. Following best practices, documenting trained models increases the transparency and explainability in ML projects. A helpful framework here is the “Model Cards Toolkit”.
Many phases in ML development are iterative. Sometimes, we might need to review the business goals, KPIs, and available data from the previous steps to adjust the outcomes of the ML model results.
Finally, we package the ML workflow in a pipeline to create repeatable model training during the modeling phase.
Evaluating Machine Learning Models
Consequently, model training is followed by a model evaluation phase, also known as offline testing. During this phase, the performance of the trained model needs to be validated on a test set. Additionally, the model robustness should be assessed using noisy or wrong input data. Furthermore, it is best practice to develop an explainable ML model to provide trust, meet regulatory requirements, and govern humans in ML-assisted decisions.
Finally, the model deployment decision should be met automatically based on success criteria or manually by domain and ML experts. Similar to the modeling phase, all outcomes of the evaluation phase need to be documented.
Deployment
The ML model deployment denotes a process of the ML model integration into the existing software system. After succeeding in the evaluation step in the ML development life cycle, the ML model is graduated to be deployed in the (pre-) production environment. Deployment approaches are specified during the first phase of the ML development life cycle. These approaches will differ depending on the use case and the training and prediction modus, either batch or online. For example, deploying an ML model means exposing its predictive functionality as interactive dashboards, precomputed predictions, wrapping the ML model as a plug-in component in a microkernel software architecture, or web service endpoint in a distributed system.
The ML model deployment includes the following tasks: inference hardware definition, model evaluation in a production environment (online testing, e.g., A/B tests), providing user acceptance and usability testing, providing a fall-back plan for model outages, and setting up the deployment strategy to roll out the new model gradually (e.g. canary or green/blue deployment).
Monitoring and Maintenance
Once the ML model has been put into production, it is essential to monitor its performance and maintain it. When an ML model performs on real-world data, the main risk is the “model staleness” effect when the performance of the ML model drops as it starts operating on unseen data. Furthermore, model performance is affected by hardware performance and the existing software stack. Therefore, the best practice to prevent the model performance drop is to perform the monitoring task when the model performance is continuously evaluated to decide whether the model needs to be re-trained. This is known as the Continued Model Evaluation pattern. The decision from the monitoring task leads to the second task - updating the ML model. Additionally to monitoring and re-training, reflecting on the business use case and the ML task might be valuable for adjusting the ML process.
Conclusion
Getting ML models in production involves many interplaying components and processes. In this article, we reviewed the CRISP-ML(Q) development lifecycle model. Overall, CRISP-ML(Q) is a systematic process model for machine learning software development that creates an awareness of possible risks and emphasizes quality assurance to diminish these risks to ensure the ML project’s success. The following table sumarizes the CRISP-ML(Q) core phases and the corresponding tasks:
| CRISP-ML(Q) Phase | Tasks |
|---|---|
| Business and Data Understanding |
- Define business objectives
- Translate business objectives into ML objectives - Collect and verify data - Assess the project feasibility - Create POC |
| Data Engineering |
- Feature selection
- Data selection - Class balancing - Cleaning data (noise reduction, data imputation) - Feature engineering (data construction) - Data augmentation - Data standartization |
| ML Model Engineering |
- Define quality measure of the model
- ML algorithm selection (baseline selection) - Adding domain knowledge to specialize the model - Model training - Optional: applying trainsfer learning (using pre-trained models) - Model compression - Ensemble learning - Documenting the ML model and experiments |
| ML Model Evaluation |
- Validate model's performance
- Determine robustess - Increase model's explainability - Make a decision whether to deploy the model - Document the evaluation phase |
| Model Deployment |
- Evaluate model under production condition
- Assure user acceptance and usability - Model governance - Deploy according to the selected strategy (A/B testing, multi-armed bandits) |
| Model Monitoring and Maintenance |
- Monitor the efficiency and efficacy of the model prediction serving
- Compare to the previously specified success criteria (thresholds) - Retrain model if required - Collect new data - Perform labelling of the new data points - Repeat tasks from the *Model Engineering* and *Model Evaluation* phases - Continuous, integration, training, and deployment of the model |
Acknowledgements
We would like to thank Alexey Grigoriev for insightful discussions and his valuable feedback for this chapter.