![]()
An Overview of the End-to-End Machine Learning Workflow
In this section, we provide a high-level overview of a typical workflow for machine learning-based software development. Generally, the goal of a machine learning project is to build a statistical model by using collected data and applying machine learning algorithms to them. Therefore, every ML-based software includes three main artifacts: Data, ML Model, and Code. Corresponding to these artifacts, the typical machine learning workflow consists of three main phases:
- Data Engineering: data acquisition & data preparation,
- ML Model Engineering: ML model training & serving, and
- Code Engineering :integrating ML model into the final product.
The Figure below shows the core steps involved in a typical ML workflow.
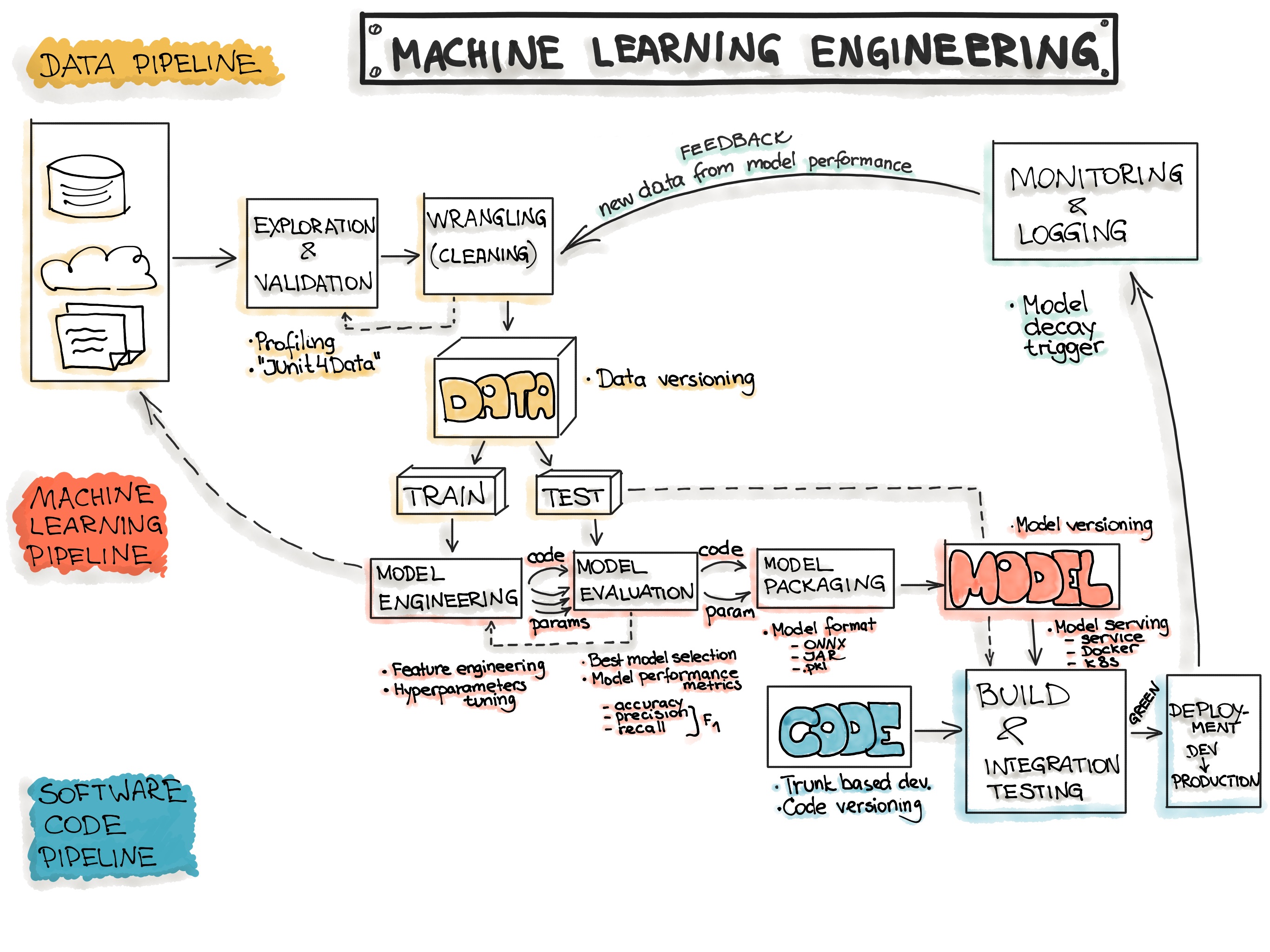
Data Engineering
The initial step in any data science workflow is to acquire and prepare the data to be analyzed. Typically, data is being integrated from various resources and has different formats. The data preparation follows the data acquisition step, which is according to Gartner “an iterative and agile process for exploring, combining, cleaning and transforming raw data into curated datasets for data integration, data science, data discovery and analytics/business intelligence (BI) use cases”. Notably, even though the preparation phase is an intermediate phase aimed to prepare data for analysis, this phase is reported to be the most expensive with respect to resources and time. Data preparation is a critical activity in the data science workflow because it is important to avoid the propagation of data errors to the next phase, data analysis, as this would result in the derivation of wrong insights from the data.
The Data Engineering pipeline includes a sequence of operations on the available data that leads to supplying training and testing datasets for the machine learning algorithms:
- Data Ingestion - Collecting data by using various frameworks and formats, such as Spark, HDFS, CSV, etc. This step might also include synthetic data generation or data enrichment.
- Exploration and Validation - Includes data profiling to obtain information about the content and structure of the data. The output of this step is a set of metadata, such as max, min, avg of values. Data validation operations are user-defined error detection functions, which scan the dataset in order to spot some errors.
- Data Wrangling (Cleaning) - The process of re-formatting particular attributes and correcting errors in data, such as missing values imputation.
- Data Labeling - The operation of the Data Engineering pipeline, where each data point is assigned to a specific category.
- Data Splitting - Splitting the data into training, validation, and test datasets to be used during the core machine learning stages to produce the ML model.
Model Engineering
The core of the ML workflow is the phase of writing and executing machine learning algorithms to obtain an ML model. The Model Engineering pipeline includes a number of operations that lead to a final model:
- Model Training - The process of applying the machine learning algorithm on training data to train an ML model. It also includes feature engineering and the hyperparameter tuning for the model training activity.
- Model Evaluation - Validating the trained model to ensure it meets original codified objectives before serving the ML model in production to the end-user.
- Model Testing - Performing the final “Model Acceptance Test” by using the hold backtest dataset.
- Model Packaging - The process of exporting the final ML model into a specific format (e.g. PMML, PFA, or ONNX), which describes the model, in order to be consumed by the business application.
Model Deployment
Once we trained a machine learning model, we need to deploy it as part of a business application such as a mobile or desktop application. The ML models require various data points (feature vector) to produce predictions. The final stage of the ML workflow is the integration of the previously engineered ML model into existing software. This stage includes the following operations:
- Model Serving - The process of addressing the ML model artifact in a production environment.
- Model Performance Monitoring - The process of observing the ML model performance based on live and previously unseen data, such as prediction or recommendation. In particular, we are interested in ML-specific signals, such as prediction deviation from previous model performance. These signals might be used as triggers for model re-training.
- Model Performance Logging - Every inference request results in the log-record.
Further reading: “Data Mesh Architecture”